What every developer should know about Surface, SurfaceHolder, EGLSurface, SurfaceView, GLSurfaceView, SurfaceTexture, TextureView, and SurfaceFlinger
This document describes the essential elements of Android's "system-level" graphics architecture, and how it is used by the application framework and multimedia system. The focus is on how buffers of graphical data move through the system. If you've ever wondered why SurfaceView and TextureView behave the way they do, or how Surface and EGLSurface interact, you've come to the right place.
Some familiarity with Android devices and application development is assumed. You don't need detailed knowledge of the app framework, and very few API calls will be mentioned, but the material herein doesn't overlap much with other public documentation. The goal here is to provide a sense for the significant events involved in rendering a frame for output, so that you can make informed choices when designing an application. To achieve this, we work from the bottom up, describing how the UI classes work rather than how they can be used.
Early sections contain background material used in later sections, so it's a good idea to read straight through rather than skipping to a section that sounds interesting. We start with an explanation of Android's graphics buffers, describe the composition and display mechanism, and then proceed to the higher-level mechanisms that supply the compositor with data.
This document is chiefly concerned with the system as it exists in Android 4.4 ("KitKat"). Earlier versions of the system worked differently, and future versions will likely be different as well. Version-specific features are called out in a few places.
At various points I will refer to source code from the AOSP sources or from Grafika. Grafika is a Google open-source project for testing; it can be found at https://github.com/google/grafika. It's more "quick hack" than solid example code, but it will suffice.
To understand how Android's graphics system works, we have to start behind the scenes. At the heart of everything graphical in Android is a class called BufferQueue. Its role is simple enough: connect something that generates buffers of graphical data (the "producer") to something that accepts the data for display or further processing (the "consumer"). The producer and consumer can live in different processes. Nearly everything that moves buffers of graphical data through the system relies on BufferQueue.
The basic usage is straightforward. The producer requests a free buffer
(dequeueBuffer()), specifying a set of characteristics including width,
height, pixel format, and usage flags. The producer populates the buffer and
returns it to the queue (queueBuffer()). Some time later, the consumer
acquires the buffer (acquireBuffer()) and makes use of the buffer contents.
When the consumer is done, it returns the buffer to the queue
(releaseBuffer()).
Most recent Android devices support the "sync framework". This allows the system to do some nifty thing when combined with hardware components that can manipulate graphics data asynchronously. For example, a producer can submit a series of OpenGL ES drawing commands and then enqueue the output buffer before rendering completes. The buffer is accompanied by a fence that signals when the contents are ready. A second fence accompanies the buffer when it is returned to the free list, so that the consumer can release the buffer while the contents are still in use. This approach improves latency and throughput as the buffers move through the system.
Some characteristics of the queue, such as the maximum number of buffers it can hold, are determined jointly by the producer and the consumer.
The BufferQueue is responsible for allocating buffers as it needs them. Buffers are retained unless the characteristics change; for example, if the producer starts requesting buffers with a different size, the old buffers will be freed and new buffers will be allocated on demand.
The data structure is currently always created and "owned" by the consumer. In Android 4.3 only the producer side was "binderized", i.e. the producer could be in a remote process but the consumer had to live in the process where the queue was created. This evolved a bit in 4.4, moving toward a more general implementation.
Buffer contents are never copied by BufferQueue. Moving that much data around would be very inefficient. Instead, buffers are always passed by handle.
The actual buffer allocations are performed through a memory allocator called
"gralloc", which is implemented through a vendor-specific HAL interface (see
hardware/libhardware/include/hardware/gralloc.h).
The alloc() function takes the arguments you'd expect -- width,
height, pixel format -- as well as a set of usage flags. Those flags merit
closer attention.
The gralloc allocator is not just another way to allocate memory on the native heap. In some situations, the allocated memory may not be cache-coherent, or could be totally inaccessible from user space. The nature of the allocation is determined by the usage flags, which include attributes like:
For example, if your format specifies RGBA 8888 pixels, and you indicate the buffer will be accessed from software -- meaning your application will touch pixels directly -- then the allocator needs to create a buffer with 4 bytes per pixel in R-G-B-A order. If instead you say the buffer will only be accessed from hardware and as a GLES texture, the allocator can do anything the GLES driver wants -- BGRA ordering, non-linear "swizzled" layouts, alternative color formats, etc. Allowing the hardware to use its preferred format can improve performance.
Some values cannot be combined on certain platforms. For example, the "video encoder" flag may require YUV pixels, so adding "software access" and specifying RGBA 8888 would fail.
The handle returned by the gralloc allocator can be passed between processes through Binder.
Having buffers of graphical data is wonderful, but life is even better when you get to see them on your device's screen. That's where SurfaceFlinger and the Hardware Composer HAL come in.
SurfaceFlinger's role is to accept buffers of data from multiple sources,
composite them, and send them to the display. Once upon a time this was done
with software blitting to a hardware framebuffer (e.g.
/dev/graphics/fb0), but those days are long gone.
When an app comes to the foreground, the WindowManager service asks SurfaceFlinger for a drawing surface. SurfaceFlinger creates a "layer" - the primary component of which is a BufferQueue - for which SurfaceFlinger acts as the consumer. A Binder object for the producer side is passed through the WindowManager to the app, which can then start sending frames directly to SurfaceFlinger. (Note: The WindowManager uses the term "window" instead of "layer" for this and uses "layer" to mean something else. We're going to use the SurfaceFlinger terminology. It can be argued that SurfaceFlinger should really be called LayerFlinger.)
For most apps, there will be three layers on screen at any time: the "status bar" at the top of the screen, the "navigation bar" at the bottom or side, and the application's UI. Some apps will have more or less, e.g. the default home app has a separate layer for the wallpaper, while a full-screen game might hide the status bar. Each layer can be updated independently. The status and navigation bars are rendered by a system process, while the app layers are rendered by the app, with no coordination between the two.
Device displays refresh at a certain rate, typically 60 frames per second on phones and tablets. If the display contents are updated mid-refresh, "tearing" will be visible; so it's important to update the contents only between cycles. The system receives a signal from the display when it's safe to update the contents. For historical reasons we'll call this the VSYNC signal.
The refresh rate may vary over time, e.g. some mobile devices will range from 58 to 62fps depending on current conditions. For an HDMI-attached television, this could theoretically dip to 24 or 48Hz to match a video. Because we can update the screen only once per refresh cycle, submitting buffers for display at 200fps would be a waste of effort as most of the frames would never be seen. Instead of taking action whenever an app submits a buffer, SurfaceFlinger wakes up when the display is ready for something new.
When the VSYNC signal arrives, SurfaceFlinger walks through its list of layers looking for new buffers. If it finds a new one, it acquires it; if not, it continues to use the previously-acquired buffer. SurfaceFlinger always wants to have something to display, so it will hang on to one buffer. If no buffers have ever been submitted on a layer, the layer is ignored.
Once SurfaceFlinger has collected all of the buffers for visible layers, it asks the Hardware Composer how composition should be performed.
The Hardware Composer HAL ("HWC") was first introduced in Android 3.0 ("Honeycomb") and has evolved steadily over the years. Its primary purpose is to determine the most efficient way to composite buffers with the available hardware. As a HAL, its implementation is device-specific and usually implemented by the display hardware OEM.
The value of this approach is easy to recognize when you consider "overlay planes." The purpose of overlay planes is to composite multiple buffers together, but in the display hardware rather than the GPU. For example, suppose you have a typical Android phone in portrait orientation, with the status bar on top and navigation bar at the bottom, and app content everywhere else. The contents for each layer are in separate buffers. You could handle composition by rendering the app content into a scratch buffer, then rendering the status bar over it, then rendering the navigation bar on top of that, and finally passing the scratch buffer to the display hardware. Or, you could pass all three buffers to the display hardware, and tell it to read data from different buffers for different parts of the screen. The latter approach can be significantly more efficient.
As you might expect, the capabilities of different display processors vary significantly. The number of overlays, whether layers can be rotated or blended, and restrictions on positioning and overlap can be difficult to express through an API. So, the HWC works like this:
Since the decision-making code can be custom tailored by the hardware vendor, it's possible to get the best performance out of every device.
Overlay planes may be less efficient than GL composition when nothing on the screen is changing. This is particularly true when the overlay contents have transparent pixels, and overlapping layers are being blended together. In such cases, the HWC can choose to request GLES composition for some or all layers and retain the composited buffer. If SurfaceFlinger comes back again asking to composite the same set of buffers, the HWC can just continue to show the previously-composited scratch buffer. This can improve the battery life of an idle device.
Devices shipping with Android 4.4 ("KitKat") typically support four overlay planes. Attempting to composite more layers than there are overlays will cause the system to use GLES composition for some of them; so the number of layers used by an application can have a measurable impact on power consumption and performance.
You can see exactly what SurfaceFlinger is up to with the command adb shell
dumpsys SurfaceFlinger. The output is verbose. The part most relevant to our
current discussion is the HWC summary that appears near the bottom of the
output:
type | source crop | frame name
------------+-----------------------------------+--------------------------------
HWC | [ 0.0, 0.0, 320.0, 240.0] | [ 48, 411, 1032, 1149] SurfaceView
HWC | [ 0.0, 75.0, 1080.0, 1776.0] | [ 0, 75, 1080, 1776] com.android.grafika/com.android.grafika.PlayMovieSurfaceActivity
HWC | [ 0.0, 0.0, 1080.0, 75.0] | [ 0, 0, 1080, 75] StatusBar
HWC | [ 0.0, 0.0, 1080.0, 144.0] | [ 0, 1776, 1080, 1920] NavigationBar
FB TARGET | [ 0.0, 0.0, 1080.0, 1920.0] | [ 0, 0, 1080, 1920] HWC_FRAMEBUFFER_TARGET
This tells you what layers are on screen, whether they're being handled with overlays ("HWC") or OpenGL ES composition ("GLES"), and gives you a bunch of other facts you probably won't care about ("handle" and "hints" and "flags" and other stuff that we've trimmed out of the snippet above). The "source crop" and "frame" values will be examined more closely later on.
The FB_TARGET layer is where GLES composition output goes. Since all layers
shown above are using overlays, FB_TARGET isn’t being used for this frame. The
layer's name is indicative of its original role: On a device with
/dev/graphics/fb0 and no overlays, all composition would be done
with GLES, and the output would be written to the framebuffer. On recent devices there
generally is no simple framebuffer, so the FB_TARGET layer is a scratch buffer.
(Note: This is why screen grabbers written for old versions of Android no
longer work: They're trying to read from The Framebuffer, but there is no such
thing.)
The overlay planes have another important role: they're the only way to display DRM content. DRM-protected buffers cannot be accessed by SurfaceFlinger or the GLES driver, which means that your video will disappear if HWC switches to GLES composition.
To avoid tearing on the display, the system needs to be double-buffered: the front buffer is displayed while the back buffer is being prepared. At VSYNC, if the back buffer is ready, you quickly switch them. This works reasonably well in a system where you're drawing directly into the framebuffer, but there's a hitch in the flow when a composition step is added. Because of the way SurfaceFlinger is triggered, our double-buffered pipeline will have a bubble.
Suppose frame N is being displayed, and frame N+1 has been acquired by SurfaceFlinger for display on the next VSYNC. (Assume frame N is composited with an overlay, so we can't alter the buffer contents until the display is done with it.) When VSYNC arrives, HWC flips the buffers. While the app is starting to render frame N+2 into the buffer that used to hold frame N, SurfaceFlinger is scanning the layer list, looking for updates. SurfaceFlinger won't find any new buffers, so it prepares to show frame N+1 again after the next VSYNC. A little while later, the app finishes rendering frame N+2 and queues it for SurfaceFlinger, but it's too late. This has effectively cut our maximum frame rate in half.
We can fix this with triple-buffering. Just before VSYNC, frame N is being displayed, frame N+1 has been composited (or scheduled for an overlay) and is ready to be displayed, and frame N+2 is queued up and ready to be acquired by SurfaceFlinger. When the screen flips, the buffers rotate through the stages with no bubble. The app has just less than a full VSYNC period (16.7ms at 60fps) to do its rendering and queue the buffer. And SurfaceFlinger / HWC has a full VSYNC period to figure out the composition before the next flip. The downside is that it takes at least two VSYNC periods for anything that the app does to appear on the screen. As the latency increases, the device feels less responsive to touch input.
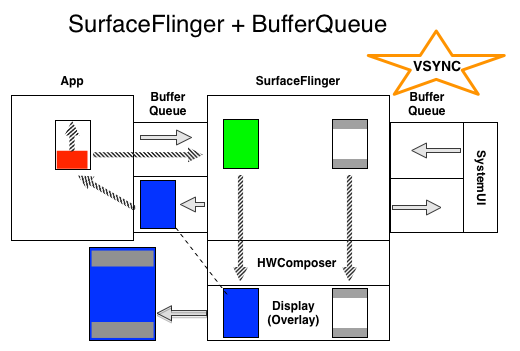
Figure 1. SurfaceFlinger + BufferQueue
The diagram above depicts the flow of SurfaceFlinger and BufferQueue. During frame:
The blue buffer is referenced by both the display and the BufferQueue. The app is not allowed to render to it until the associated sync fence signals.
On VSYNC, all of these happen at once:
* - The System UI process is providing the status and nav bars, which for our purposes here aren’t changing, so SurfaceFlinger keeps using the previously-acquired buffer. In practice there would be two separate buffers, one for the status bar at the top, one for the navigation bar at the bottom, and they would be sized to fit their contents. Each would arrive on its own BufferQueue.
** - The buffer doesn’t actually “empty”; if you submit it without drawing on it you’ll get that same blue again. The emptying is the result of clearing the buffer contents, which the app should do before it starts drawing.
We can reduce the latency by noting layer composition should not require a full VSYNC period. If composition is performed by overlays, it takes essentially zero CPU and GPU time. But we can't count on that, so we need to allow a little time. If the app starts rendering halfway between VSYNC signals, and SurfaceFlinger defers the HWC setup until a few milliseconds before the signal is due to arrive, we can cut the latency from 2 frames to perhaps 1.5. In theory you could render and composite in a single period, allowing a return to double-buffering; but getting it down that far is difficult on current devices. Minor fluctuations in rendering and composition time, and switching from overlays to GLES composition, can cause us to miss a swap deadline and repeat the previous frame.
SurfaceFlinger's buffer handling demonstrates the fence-based buffer
management mentioned earlier. If we're animating at full speed, we need to
have an acquired buffer for the display ("front") and an acquired buffer for
the next flip ("back"). If we're showing the buffer on an overlay, the
contents are being accessed directly by the display and must not be touched.
But if you look at an active layer's BufferQueue state in the dumpsys
SurfaceFlinger output, you'll see one acquired buffer, one queued buffer, and
one free buffer. That's because, when SurfaceFlinger acquires the new "back"
buffer, it releases the current "front" buffer to the queue. The "front"
buffer is still in use by the display, so anything that dequeues it must wait
for the fence to signal before drawing on it. So long as everybody follows
the fencing rules, all of the queue-management IPC requests can happen in
parallel with the display.
SurfaceFlinger supports a "primary" display, i.e. what's built into your phone or tablet, and an "external" display, such as a television connected through HDMI. It also supports a number of "virtual" displays, which make composited output available within the system. Virtual displays can be used to record the screen or send it over a network.
Virtual displays may share the same set of layers as the main display (the "layer stack") or have its own set. There is no VSYNC for a virtual display, so the VSYNC for the primary display is used to trigger composition for all displays.
In the past, virtual displays were always composited with GLES. The Hardware Composer managed composition for only the primary display. In Android 4.4, the Hardware Composer gained the ability to participate in virtual display composition.
As you might expect, the frames generated for a virtual display are written to a BufferQueue.
Now that we've established some background on BufferQueue and SurfaceFlinger, it's useful to examine a practical use case.
The screenrecord command, introduced in Android 4.4, allows you to record everything that appears on the screen as an .mp4 file on disk. To implement this, we have to receive composited frames from SurfaceFlinger, write them to the video encoder, and then write the encoded video data to a file. The video codecs are managed by a separate process - called "mediaserver" - so we have to move large graphics buffers around the system. To make it more challenging, we're trying to record 60fps video at full resolution. The key to making this work efficiently is BufferQueue.
The MediaCodec class allows an app to provide data as raw bytes in buffers, or through a Surface. We'll discuss Surface in more detail later, but for now just think of it as a wrapper around the producer end of a BufferQueue. When screenrecord requests access to a video encoder, mediaserver creates a BufferQueue and connects itself to the consumer side, and then passes the producer side back to screenrecord as a Surface.
The screenrecord command then asks SurfaceFlinger to create a virtual display that mirrors the main display (i.e. it has all of the same layers), and directs it to send output to the Surface that came from mediaserver. Note that, in this case, SurfaceFlinger is the producer of buffers rather than the consumer.
Once the configuration is complete, screenrecord can just sit and wait for encoded data to appear. As apps draw, their buffers travel to SurfaceFlinger, which composites them into a single buffer that gets sent directly to the video encoder in mediaserver. The full frames are never even seen by the screenrecord process. Internally, mediaserver has its own way of moving buffers around that also passes data by handle, minimizing overhead.
The WindowManager can ask SurfaceFlinger to create a visible layer for which SurfaceFlinger will act as the BufferQueue consumer. It's also possible to ask SurfaceFlinger to create a virtual display, for which SurfaceFlinger will act as the BufferQueue producer. What happens if you connect them, configuring a virtual display that renders to a visible layer?
You create a closed loop, where the composited screen appears in a window. Of course, that window is now part of the composited output, so on the next refresh the composited image inside the window will show the window contents as well. It's turtles all the way down. You can see this in action by enabling "Developer options" in settings, selecting "Simulate secondary displays", and enabling a window. For bonus points, use screenrecord to capture the act of enabling the display, then play it back frame-by-frame.
The Surface class has been part of the public API since 1.0. Its description simply says, "Handle onto a raw buffer that is being managed by the screen compositor." The statement was accurate when initially written but falls well short of the mark on a modern system.
The Surface represents the producer side of a buffer queue that is often (but not always!) consumed by SurfaceFlinger. When you render onto a Surface, the result ends up in a buffer that gets shipped to the consumer. A Surface is not simply a raw chunk of memory you can scribble on.
The BufferQueue for a display Surface is typically configured for
triple-buffering; but buffers are allocated on demand. So if the producer
generates buffers slowly enough -- maybe it's animating at 30fps on a 60fps
display -- there might only be two allocated buffers in the queue. This helps
minimize memory consumption. You can see a summary of the buffers associated
with every layer in the dumpsys SurfaceFlinger output.
Once upon a time, all rendering was done in software, and you can still do this
today. The low-level implementation is provided by the Skia graphics library.
If you want to draw a rectangle, you make a library call, and it sets bytes in a
buffer appropriately. To ensure that a buffer isn't updated by two clients at
once, or written to while being displayed, you have to lock the buffer to access
it. lockCanvas() locks the buffer and returns a Canvas to use for drawing,
and unlockCanvasAndPost() unlocks the buffer and sends it to the compositor.
As time went on, and devices with general-purpose 3D engines appeared, Android
reoriented itself around OpenGL ES. However, it was important to keep the old
API working, for apps as well as app framework code, so an effort was made to
hardware-accelerate the Canvas API. As you can see from the charts on the
Hardware
Acceleration
page, this was a bit of a bumpy ride. Note in particular that while the Canvas
provided to a View's onDraw() method may be hardware-accelerated, the Canvas
obtained when an app locks a Surface directly with lockCanvas() never is.
When you lock a Surface for Canvas access, the "CPU renderer" connects to the producer side of the BufferQueue and does not disconnect until the Surface is destroyed. Most other producers (like GLES) can be disconnected and reconnected to a Surface, but the Canvas-based "CPU renderer" cannot. This means you can't draw on a surface with GLES or send it frames from a video decoder if you've ever locked it for a Canvas.
The first time the producer requests a buffer from a BufferQueue, it is
allocated and initialized to zeroes. Initialization is necessary to avoid
inadvertently sharing data between processes. When you re-use a buffer,
however, the previous contents will still be present. If you repeatedly call
lockCanvas() and unlockCanvasAndPost() without
drawing anything, you'll cycle between previously-rendered frames.
The Surface lock/unlock code keeps a reference to the previously-rendered buffer. If you specify a dirty region when locking the Surface, it will copy the non-dirty pixels from the previous buffer. There's a fair chance the buffer will be handled by SurfaceFlinger or HWC; but since we need to only read from it, there's no need to wait for exclusive access.
The main non-Canvas way for an application to draw directly on a Surface is through OpenGL ES. That's described in the EGLSurface and OpenGL ES section.
Some things that work with Surfaces want a SurfaceHolder, notably SurfaceView. The original idea was that Surface represented the raw compositor-managed buffer, while SurfaceHolder was managed by the app and kept track of higher-level information like the dimensions and format. The Java-language definition mirrors the underlying native implementation. It's arguably no longer useful to split it this way, but it has long been part of the public API.
Generally speaking, anything having to do with a View will involve a SurfaceHolder. Some other APIs, such as MediaCodec, will operate on the Surface itself. You can easily get the Surface from the SurfaceHolder, so hang on to the latter when you have it.
APIs to get and set Surface parameters, such as the size and format, are implemented through SurfaceHolder.
OpenGL ES defines an API for rendering graphics. It does not define a windowing system. To allow GLES to work on a variety of platforms, it is designed to be combined with a library that knows how to create and access windows through the operating system. The library used for Android is called EGL. If you want to draw textured polygons, you use GLES calls; if you want to put your rendering on the screen, you use EGL calls.
Before you can do anything with GLES, you need to create a GL context. In EGL, this means creating an EGLContext and an EGLSurface. GLES operations apply to the current context, which is accessed through thread-local storage rather than passed around as an argument. This means you have to be careful about which thread your rendering code executes on, and which context is current on that thread.
The EGLSurface can be an off-screen buffer allocated by EGL (called a "pbuffer")
or a window allocated by the operating system. EGL window surfaces are created
with the eglCreateWindowSurface() call. It takes a "window object" as an
argument, which on Android can be a SurfaceView, a SurfaceTexture, a
SurfaceHolder, or a Surface -- all of which have a BufferQueue underneath. When
you make this call, EGL creates a new EGLSurface object, and connects it to the
producer interface of the window object's BufferQueue. From that point onward,
rendering to that EGLSurface results in a buffer being dequeued, rendered into,
and queued for use by the consumer. (The term "window" is indicative of the
expected use, but bear in mind the output might not be destined to appear
on the display.)
EGL does not provide lock/unlock calls. Instead, you issue drawing commands and
then call eglSwapBuffers() to submit the current frame. The
method name comes from the traditional swap of front and back buffers, but the actual
implementation may be very different.
Only one EGLSurface can be associated with a Surface at a time -- you can have only one producer connected to a BufferQueue -- but if you destroy the EGLSurface it will disconnect from the BufferQueue and allow something else to connect.
A given thread can switch between multiple EGLSurfaces by changing what's "current." An EGLSurface must be current on only one thread at a time.
The most common mistake when thinking about EGLSurface is assuming that it is just another aspect of Surface (like SurfaceHolder). It's a related but independent concept. You can draw on an EGLSurface that isn't backed by a Surface, and you can use a Surface without EGL. EGLSurface just gives GLES a place to draw.
The public Surface class is implemented in the Java programming language. The
equivalent in C/C++ is the ANativeWindow class, semi-exposed by the Android NDK. You
can get the ANativeWindow from a Surface with the ANativeWindow_fromSurface()
call. Just like its Java-language cousin, you can lock it, render in software,
and unlock-and-post.
To create an EGL window surface from native code, you pass an instance of
EGLNativeWindowType to eglCreateWindowSurface(). EGLNativeWindowType is just
a synonym for ANativeWindow, so you can freely cast one to the other.
The fact that the basic "native window" type just wraps the producer side of a BufferQueue should not come as a surprise.
Now that we've explored the lower-level components, it's time to see how they fit into the higher-level components that apps are built from.
The Android app framework UI is based on a hierarchy of objects that start with View. Most of the details don't matter for this discussion, but it's helpful to understand that UI elements go through a complicated measurement and layout process that fits them into a rectangular area. All visible View objects are rendered to a SurfaceFlinger-created Surface that was set up by the WindowManager when the app was brought to the foreground. The layout and rendering is performed on the app's UI thread.
Regardless of how many Layouts and Views you have, everything gets rendered into a single buffer. This is true whether or not the Views are hardware-accelerated.
A SurfaceView takes the same sorts of parameters as other views, so you can give it a position and size, and fit other elements around it. When it comes time to render, however, the contents are completely transparent. The View part of a SurfaceView is just a see-through placeholder.
When the SurfaceView's View component is about to become visible, the framework asks the WindowManager to ask SurfaceFlinger to create a new Surface. (This doesn't happen synchronously, which is why you should provide a callback that notifies you when the Surface creation finishes.) By default, the new Surface is placed behind the app UI Surface, but the default "Z-ordering" can be overridden to put the Surface on top.
Whatever you render onto this Surface will be composited by SurfaceFlinger, not by the app. This is the real power of SurfaceView: the Surface you get can be rendered by a separate thread or a separate process, isolated from any rendering performed by the app UI, and the buffers go directly to SurfaceFlinger. You can't totally ignore the UI thread -- you still have to coordinate with the Activity lifecycle, and you may need to adjust something if the size or position of the View changes -- but you have a whole Surface all to yourself, and blending with the app UI and other layers is handled by the Hardware Composer.
It's worth taking a moment to note that this new Surface is the producer side of a BufferQueue whose consumer is a SurfaceFlinger layer. You can update the Surface with any mechanism that can feed a BufferQueue. You can: use the Surface-supplied Canvas functions, attach an EGLSurface and draw on it with GLES, and configure a MediaCodec video decoder to write to it.
Now that we have a bit more context, it's useful to go back and look at a couple
of fields from dumpsys SurfaceFlinger that we skipped over earlier
on. Back in the Hardware Composer discussion, we
looked at some output like this:
type | source crop | frame name
------------+-----------------------------------+--------------------------------
HWC | [ 0.0, 0.0, 320.0, 240.0] | [ 48, 411, 1032, 1149] SurfaceView
HWC | [ 0.0, 75.0, 1080.0, 1776.0] | [ 0, 75, 1080, 1776] com.android.grafika/com.android.grafika.PlayMovieSurfaceActivity
HWC | [ 0.0, 0.0, 1080.0, 75.0] | [ 0, 0, 1080, 75] StatusBar
HWC | [ 0.0, 0.0, 1080.0, 144.0] | [ 0, 1776, 1080, 1920] NavigationBar
FB TARGET | [ 0.0, 0.0, 1080.0, 1920.0] | [ 0, 0, 1080, 1920] HWC_FRAMEBUFFER_TARGET
This was taken while playing a movie in Grafika's "Play video (SurfaceView)" activity, on a Nexus 5 in portrait orientation. Note that the list is ordered from back to front: the SurfaceView's Surface is in the back, the app UI layer sits on top of that, followed by the status and navigation bars that are above everything else. The video is QVGA (320x240).
The "source crop" indicates the portion of the Surface's buffer that SurfaceFlinger is going to display. The app UI was given a Surface equal to the full size of the display (1080x1920), but there's no point rendering and compositing pixels that will be obscured by the status and navigation bars, so the source is cropped to a rectangle that starts 75 pixels from the top, and ends 144 pixels from the bottom. The status and navigation bars have smaller Surfaces, and the source crop describes a rectangle that begins at the the top left (0,0) and spans their content.
The "frame" is the rectangle where the pixels end up on the display. For the app UI layer, the frame matches the source crop, because we're copying (or overlaying) a portion of a display-sized layer to the same location in another display-sized layer. For the status and navigation bars, the size of the frame rectangle is the same, but the position is adjusted so that the navigation bar appears at the bottom of the screen.
Now consider the layer labeled "SurfaceView", which holds our video content. The source crop matches the video size, which SurfaceFlinger knows because the MediaCodec decoder (the buffer producer) is dequeuing buffers that size. The frame rectangle has a completely different size -- 984x738.
SurfaceFlinger handles size differences by scaling the buffer contents to fill the frame rectangle, upscaling or downscaling as needed. This particular size was chosen because it has the same aspect ratio as the video (4:3), and is as wide as possible given the constraints of the View layout (which includes some padding at the edges of the screen for aesthetic reasons).
If you started playing a different video on the same Surface, the underlying BufferQueue would reallocate buffers to the new size automatically, and SurfaceFlinger would adjust the source crop. If the aspect ratio of the new video is different, the app would need to force a re-layout of the View to match it, which causes the WindowManager to tell SurfaceFlinger to update the frame rectangle.
If you're rendering on the Surface through some other means, perhaps GLES, you
can set the Surface size using the SurfaceHolder#setFixedSize()
call. You could, for example, configure a game to always render at 1280x720,
which would significantly reduce the number of pixels that must be touched to
fill the screen on a 2560x1440 tablet or 4K television. The display processor
handles the scaling. If you don't want to letter- or pillar-box your game, you
could adjust the game's aspect ratio by setting the size so that the narrow
dimension is 720 pixels, but the long dimension is set to maintain the aspect
ratio of the physical display (e.g. 1152x720 to match a 2560x1600 display).
You can see an example of this approach in Grafika's "Hardware scaler
exerciser" activity.
The GLSurfaceView class provides some helper classes that help manage EGL contexts, inter-thread communication, and interaction with the Activity lifecycle. That's it. You do not need to use a GLSurfaceView to use GLES.
For example, GLSurfaceView creates a thread for rendering and configures an EGL context there. The state is cleaned up automatically when the activity pauses. Most apps won't need to know anything about EGL to use GLES with GLSurfaceView.
In most cases, GLSurfaceView is very helpful and can make working with GLES easier. In some situations, it can get in the way. Use it if it helps, don't if it doesn't.
The SurfaceTexture class is a relative newcomer, added in Android 3.0 ("Honeycomb"). Just as SurfaceView is the combination of a Surface and a View, SurfaceTexture is the combination of a Surface and a GLES texture. Sort of.
When you create a SurfaceTexture, you are creating a BufferQueue for which your
app is the consumer. When a new buffer is queued by the producer, your app is
notified via callback (onFrameAvailable()). Your app calls
updateTexImage(), which releases the previously-held buffer,
acquires the new buffer from the queue, and makes some EGL calls to make the
buffer available to GLES as an "external" texture.
External textures (GL_TEXTURE_EXTERNAL_OES) are not quite the
same as textures created by GLES (GL_TEXTURE_2D). You have to
configure your renderer a bit differently, and there are things you can't do
with them. But the key point is this: You can render textured polygons directly
from the data received by your BufferQueue.
You may be wondering how we can guarantee the format of the data in the
buffer is something GLES can recognize -- gralloc supports a wide variety
of formats. When SurfaceTexture created the BufferQueue, it set the consumer's
usage flags to GRALLOC_USAGE_HW_TEXTURE, ensuring that any buffer
created by gralloc would be usable by GLES.
Because SurfaceTexture interacts with an EGL context, you have to be careful to call its methods from the correct thread. This is spelled out in the class documentation.
If you look deeper into the class documentation, you will see a couple of odd
calls. One retrieves a timestamp, the other a transformation matrix, the value
of each having been set by the previous call to updateTexImage().
It turns out that BufferQueue passes more than just a buffer handle to the consumer.
Each buffer is accompanied by a timestamp and transformation parameters.
The transformation is provided for efficiency. In some cases, the source data might be in the "wrong" orientation for the consumer; but instead of rotating the data before sending it, we can send the data in its current orientation with a transform that corrects it. The transformation matrix can be merged with other transformations at the point the data is used, minimizing overhead.
The timestamp is useful for certain buffer sources. For example, suppose you
connect the producer interface to the output of the camera (with
setPreviewTexture()). If you want to create a video, you need to
set the presentation time stamp for each frame; but you want to base that on the time
when the frame was captured, not the time when the buffer was received by your
app. The timestamp provided with the buffer is set by the camera code,
resulting in a more consistent series of timestamps.
If you look closely at the API you'll see the only way for an application to create a plain Surface is through a constructor that takes a SurfaceTexture as the sole argument. (Prior to API 11, there was no public constructor for Surface at all.) This might seem a bit backward if you view SurfaceTexture as a combination of a Surface and a texture.
Under the hood, SurfaceTexture is called GLConsumer, which more accurately reflects its role as the owner and consumer of a BufferQueue. When you create a Surface from a SurfaceTexture, what you're doing is creating an object that represents the producer side of the SurfaceTexture's BufferQueue.
The camera can provide a stream of frames suitable for recording as a movie. If
you want to display it on screen, you create a SurfaceView, pass the Surface to
setPreviewDisplay(), and let the producer (camera) and consumer
(SurfaceFlinger) do all the work. If you want to record the video, you create a
Surface with MediaCodec's createInputSurface(), pass that to the
camera, and again you sit back and relax. If you want to show the video and
record it at the same time, you have to get more involved.
The "Continuous capture" activity displays video from the camera as it's being recorded. In this case, encoded video is written to a circular buffer in memory that can be saved to disk at any time. It's straightforward to implement so long as you keep track of where everything is.
There are three BufferQueues involved. The app uses a SurfaceTexture to receive frames from Camera, converting them to an external GLES texture. The app declares a SurfaceView, which we use to display the frames, and we configure a MediaCodec encoder with an input Surface to create the video. So one BufferQueue is created by the app, one by SurfaceFlinger, and one by mediaserver.
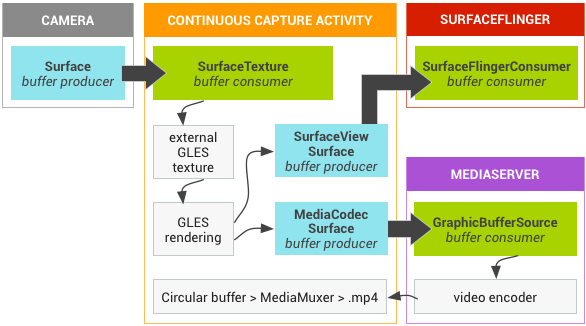
Figure 2.Grafika's continuous capture activity
In the diagram above, the arrows show the propagation of the data from the camera. BufferQueues are in color (purple producer, cyan consumer). Note “Camera” actually lives in the mediaserver process.
Encoded H.264 video goes to a circular buffer in RAM in the app process, and is written to an MP4 file on disk using the MediaMuxer class when the “capture” button is hit.
All three of the BufferQueues are handled with a single EGL context in the app, and the GLES operations are performed on the UI thread. Doing the SurfaceView rendering on the UI thread is generally discouraged, but since we're doing simple operations that are handled asynchronously by the GLES driver we should be fine. (If the video encoder locks up and we block trying to dequeue a buffer, the app will become unresponsive. But at that point, we're probably failing anyway.) The handling of the encoded data -- managing the circular buffer and writing it to disk -- is performed on a separate thread.
The bulk of the configuration happens in the SurfaceView's surfaceCreated()
callback. The EGLContext is created, and EGLSurfaces are created for the
display and for the video encoder. When a new frame arrives, we tell
SurfaceTexture to acquire it and make it available as a GLES texture, then
render it with GLES commands on each EGLSurface (forwarding the transform and
timestamp from SurfaceTexture). The encoder thread pulls the encoded output
from MediaCodec and stashes it in memory.
The TextureView class was introduced in Android 4.0 ("Ice Cream Sandwich"). It's the most complex of the View objects discussed here, combining a View with a SurfaceTexture.
Recall that the SurfaceTexture is a "GL consumer", consuming buffers of graphics data and making them available as textures. TextureView wraps a SurfaceTexture, taking over the responsibility of responding to the callbacks and acquiring new buffers. The arrival of new buffers causes TextureView to issue a View invalidate request. When asked to draw, the TextureView uses the contents of the most recently received buffer as its data source, rendering wherever and however the View state indicates it should.
You can render on a TextureView with GLES just as you would SurfaceView. Just pass the SurfaceTexture to the EGL window creation call. However, doing so exposes a potential problem.
In most of what we've looked at, the BufferQueues have passed buffers between different processes. When rendering to a TextureView with GLES, both producer and consumer are in the same process, and they might even be handled on a single thread. Suppose we submit several buffers in quick succession from the UI thread. The EGL buffer swap call will need to dequeue a buffer from the BufferQueue, and it will stall until one is available. There won't be any available until the consumer acquires one for rendering, but that also happens on the UI thread… so we're stuck.
The solution is to have BufferQueue ensure there is always a buffer available to be dequeued, so the buffer swap never stalls. One way to guarantee this is to have BufferQueue discard the contents of the previously-queued buffer when a new buffer is queued, and to place restrictions on minimum buffer counts and maximum acquired buffer counts. (If your queue has three buffers, and all three buffers are acquired by the consumer, then there's nothing to dequeue and the buffer swap call must hang or fail. So we need to prevent the consumer from acquiring more than two buffers at once.) Dropping buffers is usually undesirable, so it's only enabled in specific situations, such as when the producer and consumer are in the same process.
Because TextureView is a proper citizen of the View hierarchy, it behaves like any other View, and can overlap or be overlapped by other elements. You can perform arbitrary transformations and retrieve the contents as a bitmap with simple API calls.
The main strike against TextureView is the performance of the composition step. With SurfaceView, the content is written to a separate layer that SurfaceFlinger composites, ideally with an overlay. With TextureView, the View composition is always performed with GLES, and updates to its contents may cause other View elements to redraw as well (e.g. if they're positioned on top of the TextureView). After the View rendering completes, the app UI layer must then be composited with other layers by SurfaceFlinger, so you're effectively compositing every visible pixel twice. For a full-screen video player, or any other application that is effectively just UI elements layered on top of video, SurfaceView offers much better performance.
As noted earlier, DRM-protected video can be presented only on an overlay plane. Video players that support protected content must be implemented with SurfaceView.
Grafika includes a pair of video players, one implemented with TextureView, the other with SurfaceView. The video decoding portion, which just sends frames from MediaCodec to a Surface, is the same for both. The most interesting differences between the implementations are the steps required to present the correct aspect ratio.
While SurfaceView requires a custom implementation of FrameLayout, resizing
SurfaceTexture is a simple matter of configuring a transformation matrix with
TextureView#setTransform(). For the former, you're sending new
window position and size values to SurfaceFlinger through WindowManager; for
the latter, you're just rendering it differently.
Otherwise, both implementations follow the same pattern. Once the Surface has been created, playback is enabled. When "play" is hit, a video decoding thread is started, with the Surface as the output target. After that, the app code doesn't have to do anything -- composition and display will either be handled by SurfaceFlinger (for the SurfaceView) or by TextureView.
This activity demonstrates manipulation of the SurfaceTexture inside a TextureView.
The basic structure of this activity is a pair of TextureViews that show two different videos playing side-by-side. To simulate the needs of a videoconferencing app, we want to keep the MediaCodec decoders alive when the activity is paused and resumed for an orientation change. The trick is that you can't change the Surface that a MediaCodec decoder uses without fully reconfiguring it, which is a fairly expensive operation; so we want to keep the Surface alive. The Surface is just a handle to the producer interface in the SurfaceTexture's BufferQueue, and the SurfaceTexture is managed by the TextureView;, so we also need to keep the SurfaceTexture alive. So how do we deal with the TextureView getting torn down?
It just so happens TextureView provides a setSurfaceTexture() call
that does exactly what we want. We obtain references to the SurfaceTextures
from the TextureViews and save them in a static field. When the activity is
shut down, we return "false" from the onSurfaceTextureDestroyed()
callback to prevent destruction of the SurfaceTexture. When the activity is
restarted, we stuff the old SurfaceTexture into the new TextureView. The
TextureView class takes care of creating and destroying the EGL contexts.
Each video decoder is driven from a separate thread. At first glance it might seem like we need EGL contexts local to each thread; but remember the buffers with decoded output are actually being sent from mediaserver to our BufferQueue consumers (the SurfaceTextures). The TextureViews take care of the rendering for us, and they execute on the UI thread.
Implementing this activity with SurfaceView would be a bit harder. We can't just create a pair of SurfaceViews and direct the output to them, because the Surfaces would be destroyed during an orientation change. Besides, that would add two layers, and limitations on the number of available overlays strongly motivate us to keep the number of layers to a minimum. Instead, we'd want to create a pair of SurfaceTextures to receive the output from the video decoders, and then perform the rendering in the app, using GLES to render two textured quads onto the SurfaceView's Surface.
We hope this page has provided useful insights into the way Android handles graphics at the system level.
Some information and advice on related topics can be found in the appendices that follow.
A very popular way to implement a game loop looks like this:
while (playing) {
advance state by one frame
render the new frame
sleep until it’s time to do the next frame
}
There are a few problems with this, the most fundamental being the idea that the game can define what a "frame" is. Different displays will refresh at different rates, and that rate may vary over time. If you generate frames faster than the display can show them, you will have to drop one occasionally. If you generate them too slowly, SurfaceFlinger will periodically fail to find a new buffer to acquire and will re-show the previous frame. Both of these situations can cause visible glitches.
What you need to do is match the display's frame rate, and advance game state according to how much time has elapsed since the previous frame. There are two ways to go about this: (1) stuff the BufferQueue full and rely on the "swap buffers" back-pressure; (2) use Choreographer (API 16+).
This is very easy to implement: just swap buffers as fast as you can. In early
versions of Android this could actually result in a penalty where
SurfaceView#lockCanvas() would put you to sleep for 100ms. Now
it's paced by the BufferQueue, and the BufferQueue is emptied as quickly as
SurfaceFlinger is able.
One example of this approach can be seen in Android Breakout. It
uses GLSurfaceView, which runs in a loop that calls the application's
onDrawFrame() callback and then swaps the buffer. If the BufferQueue is full,
the eglSwapBuffers() call will wait until a buffer is available.
Buffers become available when SurfaceFlinger releases them, which it does after
acquiring a new one for display. Because this happens on VSYNC, your draw loop
timing will match the refresh rate. Mostly.
There are a couple of problems with this approach. First, the app is tied to SurfaceFlinger activity, which is going to take different amounts of time depending on how much work there is to do and whether it's fighting for CPU time with other processes. Since your game state advances according to the time between buffer swaps, your animation won't update at a consistent rate. When running at 60fps with the inconsistencies averaged out over time, though, you probably won't notice the bumps.
Second, the first couple of buffer swaps are going to happen very quickly because the BufferQueue isn't full yet. The computed time between frames will be near zero, so the game will generate a few frames in which nothing happens. In a game like Breakout, which updates the screen on every refresh, the queue is always full except when a game is first starting (or un-paused), so the effect isn't noticeable. A game that pauses animation occasionally and then returns to as-fast-as-possible mode might see odd hiccups.
Choreographer allows you to set a callback that fires on the next VSYNC. The actual VSYNC time is passed in as an argument. So even if your app doesn't wake up right away, you still have an accurate picture of when the display refresh period began. Using this value, rather than the current time, yields a consistent time source for your game state update logic.
Unfortunately, the fact that you get a callback after every VSYNC does not guarantee that your callback will be executed in a timely fashion or that you will be able to act upon it sufficiently swiftly. Your app will need to detect situations where it's falling behind and drop frames manually.
The "Record GL app" activity in Grafika provides an example of this. On some devices (e.g. Nexus 4 and Nexus 5), the activity will start dropping frames if you just sit and watch. The GL rendering is trivial, but occasionally the View elements get redrawn, and the measure/layout pass can take a very long time if the device has dropped into a reduced-power mode. (According to systrace, it takes 28ms instead of 6ms after the clocks slow on Android 4.4. If you drag your finger around the screen, it thinks you're interacting with the activity, so the clock speeds stay high and you'll never drop a frame.)
The simple fix was to drop a frame in the Choreographer callback if the current time is more than N milliseconds after the VSYNC time. Ideally the value of N is determined based on previously observed VSYNC intervals. For example, if the refresh period is 16.7ms (60fps), you might drop a frame if you're running more than 15ms late.
If you watch "Record GL app" run, you will see the dropped-frame counter increase, and even see a flash of red in the border when frames drop. Unless your eyes are very good, though, you won't see the animation stutter. At 60fps, the app can drop the occasional frame without anyone noticing so long as the animation continues to advance at a constant rate. How much you can get away with depends to some extent on what you're drawing, the characteristics of the display, and how good the person using the app is at detecting jank.
Generally speaking, if you're rendering onto a SurfaceView, GLSurfaceView, or TextureView, you want to do that rendering in a dedicated thread. Never do any "heavy lifting" or anything that takes an indeterminate amount of time on the UI thread.
Breakout and "Record GL app" use dedicated renderer threads, and they also update animation state on that thread. This is a reasonable approach so long as game state can be updated quickly.
Other games separate the game logic and rendering completely. If you had a simple game that did nothing but move a block every 100ms, you could have a dedicated thread that just did this:
run() {
Thread.sleep(100);
synchronized (mLock) {
moveBlock();
}
}
(You may want to base the sleep time off of a fixed clock to prevent drift -- sleep() isn't perfectly consistent, and moveBlock() takes a nonzero amount of time -- but you get the idea.)
When the draw code wakes up, it just grabs the lock, gets the current position of the block, releases the lock, and draws. Instead of doing fractional movement based on inter-frame delta times, you just have one thread that moves things along and another thread that draws things wherever they happen to be when the drawing starts.
For a scene with any complexity you'd want to create a list of upcoming events sorted by wake time, and sleep until the next event is due, but it's the same idea.
When using a SurfaceView, it's considered good practice to render the Surface from a thread other than the main UI thread. This raises some questions about the interaction between that thread and the Activity lifecycle.
First, a little background. For an Activity with a SurfaceView, there are two separate but interdependent state machines:
When the Activity starts, you get callbacks in this order:
If you hit "back" you get:
If you rotate the screen, the Activity is torn down and recreated, so you
get the full cycle. If it matters, you can tell that it's a "quick" restart by
checking isFinishing(). (It might be possible to start / stop an
Activity so quickly that surfaceCreated() might actually happen after onPause().)
If you tap the power button to blank the screen, you only get
onPause() -- no surfaceDestroyed(). The Surface
remains alive, and rendering can continue. You can even keep getting
Choreographer events if you continue to request them. If you have a lock
screen that forces a different orientation, your Activity may be restarted when
the device is unblanked; but if not, you can come out of screen-blank with the
same Surface you had before.
This raises a fundamental question when using a separate renderer thread with SurfaceView: Should the lifespan of the thread be tied to that of the Surface or the Activity? The answer depends on what you want to have happen when the screen goes blank. There are two basic approaches: (1) start/stop the thread on Activity start/stop; (2) start/stop the thread on Surface create/destroy.
#1 interacts well with the app lifecycle. We start the renderer thread in
onResume() and stop it in onPause(). It gets a bit
awkward when creating and configuring the thread because sometimes the Surface
will already exist and sometimes it won't (e.g. it's still alive after toggling
the screen with the power button). We have to wait for the surface to be
created before we do some initialization in the thread, but we can't simply do
it in the surfaceCreated() callback because that won't fire again
if the Surface didn't get recreated. So we need to query or cache the Surface
state, and forward it to the renderer thread. Note we have to be a little
careful here passing objects between threads -- it is best to pass the Surface or
SurfaceHolder through a Handler message, rather than just stuffing it into the
thread, to avoid issues on multi-core systems (cf. the Android SMP
Primer).
#2 has a certain appeal because the Surface and the renderer are logically
intertwined. We start the thread after the Surface has been created, which
avoids some inter-thread communication concerns. Surface created / changed
messages are simply forwarded. We need to make sure rendering stops when the
screen goes blank, and resumes when it un-blanks; this could be a simple matter
of telling Choreographer to stop invoking the frame draw callback. Our
onResume() will need to resume the callbacks if and only if the
renderer thread is running. It may not be so trivial though -- if we animate
based on elapsed time between frames, we could have a very large gap when the
next event arrives; so an explicit pause/resume message may be desirable.
The above is primarily concerned with how the renderer thread is configured and
whether it's executing. A related concern is extracting state from the thread
when the Activity is killed (in onPause() or onSaveInstanceState()).
Approach #1 will work best for that, because once the renderer thread has been
joined its state can be accessed without synchronization primitives.
You can see an example of approach #2 in Grafika's "Hardware scaler exerciser."
If you really want to understand how graphics buffers move around, you need to use systrace. The system-level graphics code is well instrumented, as is much of the relevant app framework code. Enable the "gfx" and "view" tags, and generally "sched" as well.
A full description of how to use systrace effectively would fill a rather long document. One noteworthy item is the presence of BufferQueues in the trace. If you've used systrace before, you've probably seen them, but maybe weren't sure what they were. As an example, if you grab a trace while Grafika's "Play video (SurfaceView)" is running, you will see a row labeled: "SurfaceView" This row tells you how many buffers were queued up at any given time.
You'll notice the value increments while the app is active -- triggering the rendering of frames by the MediaCodec decoder -- and decrements while SurfaceFlinger is doing work, consuming buffers. If you're showing video at 30fps, the queue's value will vary from 0 to 1, because the ~60fps display can easily keep up with the source. (You'll also notice that SurfaceFlinger is only waking up when there's work to be done, not 60 times per second. The system tries very hard to avoid work and will disable VSYNC entirely if nothing is updating the screen.)
If you switch to "Play video (TextureView)" and grab a new trace, you'll see a row with a much longer name ("com.android.grafika/com.android.grafika.PlayMovieActivity"). This is the main UI layer, which is of course just another BufferQueue. Because TextureView renders into the UI layer, rather than a separate layer, you'll see all of the video-driven updates here.
For more information about systrace, see the Android documentation for the tool.