Follow the instructions here to implement the Android graphics HAL.
The following list and sections describe what you need to provide to support graphics in your product:
You must provide drivers for OpenGL ES 1.x, OpenGL ES 2.0, and EGL. Here are some key considerations:
GL_OES_texture_external,
EGL_ANDROID_image_native_buffer, and
EGL_ANDROID_recordable. The
EGL_ANDROID_framebuffer_target extension is required for Hardware
Composer 1.1 and higher, as well. EGL_ANDROID_blob_cache, EGL_KHR_fence_sync,
EGL_KHR_wait_sync, and EGL_ANDROID_native_fence_sync.
Note the OpenGL API exposed to app developers is different from the OpenGL interface that you are implementing. Apps do not have access to the GL driver layer and must go through the interface provided by the APIs.
Many hardware overlays do not support rotation, and even if they do it costs
processing power. So the solution is to pre-transform the buffer before it
reaches SurfaceFlinger. A query hint in ANativeWindow was added
(NATIVE_WINDOW_TRANSFORM_HINT) that represents the most likely
transform to be applied to the buffer by SurfaceFlinger. Your GL driver can use
this hint to pre-transform the buffer before it reaches SurfaceFlinger so when
the buffer arrives, it is correctly transformed.
For example, you may receive a hint to rotate 90 degrees. You must generate
a matrix and apply it to the buffer to prevent it from running off the end of
the page. To save power, this should be done in pre-rotation. See the
ANativeWindow interface defined in
system/core/include/system/window.h for more details.
The graphics memory allocator is needed to allocate memory that is requested
by image producers. You can find the interface definition of the HAL at:
hardware/libhardware/modules/gralloc.h
The gralloc usage flag GRALLOC_USAGE_PROTECTED allows the
graphics buffer to be displayed only through a hardware-protected path. These
overlay planes are the only way to display DRM content. DRM-protected buffers
cannot be accessed by SurfaceFlinger or the OpenGL ES driver.
DRM-protected video can be presented only on an overlay plane. Video players that support protected content must be implemented with SurfaceView. Software running on unprotected hardware cannot read or write the buffer. Hardware-protected paths must appear on the Hardware Composer overlay. For instance, protected videos will disappear from the display if Hardware Composer switches to OpenGL ES composition.
See the DRM page for a description of protected content.
The Hardware Composer HAL is used by SurfaceFlinger to composite surfaces to the screen. The Hardware Composer abstracts objects like overlays and 2D blitters and helps offload some work that would normally be done with OpenGL.
We recommend you start using version 1.3 of the Hardware Composer HAL as it will provide support for the newest features (explicit synchronization, external displays, and more). Because the physical display hardware behind the Hardware Composer abstraction layer can vary from device to device, it is difficult to define recommended features. But here is some guidance:
The general recommendation when implementing your Hardware Composer is to implement a non-operational Hardware Composer first. Once you have the structure done, implement a simple algorithm to delegate composition to the Hardware Composer. For example, just delegate the first three or four surfaces to the overlay hardware of the Hardware Composer.
Focus on optimization, such as intelligently selecting the surfaces to send to the overlay hardware that maximizes the load taken off of the GPU. Another optimization is to detect whether the screen is updating. If not, delegate composition to OpenGL instead of the Hardware Composer to save power. When the screen updates again, continue to offload composition to the Hardware Composer.
Devices must report the display mode (or resolution). Android uses the first mode reported by the device. To support televisions, have the TV device report the mode selected for it by the manufacturer to Hardware Composer. See hwcomposer.h for more details.
Prepare for common use cases, such as:
These use cases should address regular, predictable uses rather than edge cases that are rarely encountered. Otherwise, any optimization will have little benefit. Implementations must balance two competing goals: animation smoothness and interaction latency.
Further, to make best use of Android graphics, you must develop a robust clocking strategy. Performance matters little if clocks have been turned down to make every operation slow. You need a clocking strategy that puts the clocks at high speed when needed, such as to make animations seamless, and then slows the clocks whenever the increased speed is no longer needed.
Use the adb shell dumpsys SurfaceFlinger command to see
precisely what SurfaceFlinger is doing. See the Hardware
Composer section of the Architecture page for example output and a
description of relevant fields.
You can find the HAL for the Hardware Composer and additional documentation
in: hardware/libhardware/include/hardware/hwcomposer.h
hardware/libhardware/include/hardware/hwcomposer_defs.h
A stub implementation is available in the
hardware/libhardware/modules/hwcomposer directory.
VSYNC synchronizes certain events to the refresh cycle of the display. Applications always start drawing on a VSYNC boundary, and SurfaceFlinger always composites on a VSYNC boundary. This eliminates stutters and improves visual performance of graphics. The Hardware Composer has a function pointer:
int (waitForVsync*) (int64_t *timestamp)
This points to a function you must implement for VSYNC. This function blocks until a VSYNC occurs and returns the timestamp of the actual VSYNC. A message must be sent every time VSYNC occurs. A client can receive a VSYNC timestamp once, at specified intervals, or continuously (interval of 1). You must implement VSYNC to have no more than a 1ms lag at the maximum (0.5ms or less is recommended), and the timestamps returned must be extremely accurate.
Explicit synchronization is required and provides a mechanism for Gralloc buffers to be acquired and released in a synchronized way. Explicit synchronization allows producers and consumers of graphics buffers to signal when they are done with a buffer. This allows the Android system to asynchronously queue buffers to be read or written with the certainty that another consumer or producer does not currently need them. See the Synchronization framework section for an overview of this mechanism.
The benefits of explicit synchronization include less behavior variation between devices, better debugging support, and improved testing metrics. For instance, the sync framework output readily identifies problem areas and root causes. And centralized SurfaceFlinger presentation timestamps show when events occur in the normal flow of the system.
This communication is facilitated by the use of synchronization fences, which are now required when requesting a buffer for consuming or producing. The synchronization framework consists of three main building blocks: sync_timeline, sync_pt, and sync_fence.
A sync_timeline is a monotonically increasing timeline that should be implemented for each driver instance, such as a GL context, display controller, or 2D blitter. This is essentially a counter of jobs submitted to the kernel for a particular piece of hardware. It provides guarantees about the order of operations and allows hardware-specific implementations.
Please note, the sync_timeline is offered as a CPU-only reference implementation called sw_sync (which stands for software sync). If possible, use sw_sync instead of a sync_timeline to save resources and avoid complexity. If you’re not employing a hardware resource, sw_sync should be sufficient.
If you must implement a sync_timeline, use the sw_sync driver as a starting point. Follow these guidelines:
When implementing a sync_timeline, don’t:
A sync_pt is a single value or point on a sync_timeline. A point has three states: active, signaled, and error. Points start in the active state and transition to the signaled or error states. For instance, when a buffer is no longer needed by an image consumer, this sync_point is signaled so that image producers know it is okay to write into the buffer again.
A sync_fence is a collection of sync_pts that often have different sync_timeline parents (such as for the display controller and GPU). These are the main primitives over which drivers and userspace communicate their dependencies. A fence is a promise from the kernel that it gives upon accepting work that has been queued and assures completion in a finite amount of time.
This allows multiple consumers or producers to signal they are using a buffer and to allow this information to be communicated with one function parameter. Fences are backed by a file descriptor and can be passed from kernel-space to user-space. For instance, a fence can contain two sync_points that signify when two separate image consumers are done reading a buffer. When the fence is signaled, the image producers know both consumers are done consuming. Fences, like sync_pts, start active and then change state based upon the state of their points. If all sync_pts become signaled, the sync_fence becomes signaled. If one sync_pt falls into an error state, the entire sync_fence has an error state. Membership in the sync_fence is immutable once the fence is created. And since a sync_pt can be in only one fence, it is included as a copy. Even if two points have the same value, there will be two copies of the sync_pt in the fence. To get more than one point in a fence, a merge operation is conducted. In the merge, the points from two distinct fences are added to a third fence. If one of those points was signaled in the originating fence, and the other was not, the third fence will also not be in a signaled state.
To implement explicit synchronization, you need to provide the following:
kernel/common/include/linux/sync.h kernel/common/drivers/base/sync.c kernel/common/include/linux/sw_sync.h kernel/common/drivers/base/sw_sync.c kernel/common//Documentation/sync.txt Finally, the
platform/system/core/libsync directory includes a library to
communicate with the kernel-space. EGL_ANDROID_native_fence_sync and
EGL_ANDROID_wait_sync, along with incorporating fence support into
your graphics drivers. For example, to use the API supporting the synchronization function, you might develop a display driver that has a display buffer function. Before the synchronization framework existed, this function would receive dma-bufs, put those buffers on the display, and block while the buffer is visible, like so:
/* * assumes buf is ready to be displayed. returns when buffer is no longer on * screen. */ void display_buffer(struct dma_buf *buf);
With the synchronization framework, the API call is slightly more complex. While putting a buffer on display, you associate it with a fence that says when the buffer will be ready. So you queue up the work, which you will initiate once the fence clears.
In this manner, you are not blocking anything. You immediately return your own fence, which is a guarantee of when the buffer will be off of the display. As you queue up buffers, the kernel will list dependencies. With the synchronization framework:
/* * will display buf when fence is signaled. returns immediately with a fence * that will signal when buf is no longer displayed. */ struct sync_fence* display_buffer(struct dma_buf *buf, struct sync_fence *fence);
This section explains how to integrate the low-level sync framework with different parts of the Android framework and the drivers that need to communicate with one another.
The Android HAL interfaces for graphics follow consistent conventions so when file descriptors are passed across a HAL interface, ownership of the file descriptor is always transferred. This means:
Every time a fence is passed through BufferQueue - such as for a window that
passes a fence to BufferQueue saying when its new contents will be ready - the
fence object is renamed. Since kernel fence support allows fences to have
strings for names, the sync framework uses the window name and buffer index
that is being queued to name the fence, for example:
SurfaceView:0
This is helpful in debugging to identify the source of a deadlock. Those
names appear in the output of /d/sync and bug reports when
taken.
ANativeWindow is fence aware. dequeueBuffer,
queueBuffer, and cancelBuffer have fence
parameters.
OpenGL ES sync integration relies upon these two EGL extensions:
EGL_ANDROID_native_fence_sync - provides a way to either
wrap or create native Android fence file descriptors in EGLSyncKHR objects.
EGL_ANDROID_wait_sync - allows GPU-side stalls rather than in
CPU, making the GPU wait for an EGLSyncKHR. This is essentially the same as the
EGL_KHR_wait_sync extension. See the
EGL_KHR_wait_sync specification for details. These extensions can be used independently and are controlled by a compile
flag in libgui. To use them, first implement the
EGL_ANDROID_native_fence_sync extension along with the associated
kernel support. Next add a ANativeWindow support for fences to your driver and
then turn on support in libgui to make use of the
EGL_ANDROID_native_fence_sync extension.
Then, as a second pass, enable the EGL_ANDROID_wait_sync
extension in your driver and turn it on separately. The
EGL_ANDROID_native_fence_sync extension consists of a distinct
native fence EGLSync object type so extensions that apply to existing EGLSync
object types don’t necessarily apply to EGL_ANDROID_native_fence
objects to avoid unwanted interactions.
The EGL_ANDROID_native_fence_sync extension employs a corresponding native fence file descriptor attribute that can be set only at creation time and cannot be directly queried onward from an existing sync object. This attribute can be set to one of two modes:
The DupNativeFenceFD function call is used to extract the EGLSyncKHR object from the native Android fence file descriptor. This has the same result as querying the attribute that was set but adheres to the convention that the recipient closes the fence (hence the duplicate operation). Finally, destroying the EGLSync object should close the internal fence attribute.
Hardware Composer handles three types of sync fences:
The retire fence can be used to determine how long each frame appears on the screen. This is useful in identifying the location and source of delays, such as a stuttering animation.
Application and SurfaceFlinger render loops should be synchronized to the hardware VSYNC. On a VSYNC event, the display begins showing frame N while SurfaceFlinger begins compositing windows for frame N+1. The app handles pending input and generates frame N+2.
Synchronizing with VSYNC delivers consistent latency. It reduces errors in apps and SurfaceFlinger and the drifting of displays in and out of phase with each other. This, however, does assume application and SurfaceFlinger per-frame times don’t vary widely. Nevertheless, the latency is at least two frames.
To remedy this, you may employ VSYNC offsets to reduce the input-to-display latency by making application and composition signal relative to hardware VSYNC. This is possible because application plus composition usually takes less than 33 ms.
The result of VSYNC offset is three signals with same period, offset phase:
With VSYNC offset, SurfaceFlinger receives the buffer and composites the frame, while the application processes the input and renders the frame, all within a single frame of time.
Please note, VSYNC offsets reduce the time available for app and composition and therefore provide a greater chance for error.
DispSync maintains a model of the periodic hardware-based VSYNC events of a display and uses that model to execute periodic callbacks at specific phase offsets from the hardware VSYNC events.
DispSync is essentially a software phase lock loop (PLL) that generates the VSYNC and SF VSYNC signals used by Choreographer and SurfaceFlinger, even if not offset from hardware VSYNC.
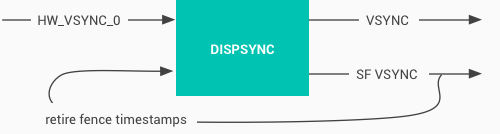
Figure 4. DispSync flow
DispSync has these qualities:
The signal timestamp of retire fences must match HW VSYNC even on devices that don’t use the offset phase. Otherwise, errors appear to have greater severity than reality.
“Smart” panels often have a delta. Retire fence is the end of direct memory access (DMA) to display memory. The actual display switch and HW VSYNC is some time later.
PRESENT_TIME_OFFSET_FROM_VSYNC_NS is set in the device’s
BoardConfig.mk make file. It is based upon the display controller and panel
characteristics. Time from retire fence timestamp to HW Vsync signal is
measured in nanoseconds.
The VSYNC_EVENT_PHASE_OFFSET_NS and
SF_VSYNC_EVENT_PHASE_OFFSET_NS are set conservatively based on
high-load use cases, such as partial GPU composition during window transition
or Chrome scrolling through a webpage containing animations. These offsets
allow for long application render time and long GPU composition time.
More than a millisecond or two of latency is noticeable. We recommend integrating thorough automated error testing to minimize latency without significantly increasing error counts.
Note these offsets are also set in the device’s BoardConfig.mk make file. The default if not set is zero offset. Both settings are offset in nanoseconds after HW_VSYNC_0. Either can be negative.
Android added support for virtual displays to Hardware Composer in version 1.3. This support was implemented in the Android platform and can be used by Miracast.
The virtual display composition is similar to the physical display: Input layers are described in prepare(), SurfaceFlinger conducts GPU composition, and layers and GPU framebuffer are provided to Hardware Composer in set().
Instead of the output going to the screen, it is sent to a gralloc buffer. Hardware Composer writes output to a buffer and provides the completion fence. The buffer is sent to an arbitrary consumer: video encoder, GPU, CPU, etc. Virtual displays can use 2D/blitter or overlays if the display pipeline can write to memory.
Each frame is in one of three modes after prepare():
MIXED and HWC modes: If the consumer needs CPU access, the consumer chooses the format. Otherwise, the format is IMPLEMENTATION_DEFINED. Gralloc can choose best format based on usage flags. For example, choose a YCbCr format if the consumer is video encoder, and Hardware Composer can write the format efficiently.
GLES mode: EGL driver chooses output buffer format in dequeueBuffer(), typically RGBA8888. The consumer must be able to accept this format.
Hardware Composer 1.3 virtual displays require that eglSwapBuffers() does not dequeue the next buffer immediately. Instead, it should defer dequeueing the buffer until rendering begins. Otherwise, EGL always owns the “next” output buffer. SurfaceFlinger can’t get the output buffer for Hardware Composer in MIXED/HWC mode.
If Hardware Composer always sends all virtual display layers to GPU, all frames will be in GLES mode. Although it is not recommended, you may use this method if you need to support Hardware Composer 1.3 for some other reason but can’t conduct virtual display composition.
For benchmarking, we suggest following this flow by phase:
For the specification phase, Android offers the Flatland tool to help derive
device capabilities. It can be found at:
platform/frameworks/native/cmds/flatland/
Flatland relies upon fixed clocks and shows the throughput that can be achieved with composition-based workloads. It uses gralloc buffers to simulate multiple window scenarios, filling in the window with GL and then measuring the compositing. Please note, Flatland uses the synchronization framework to measure time. So you must support the synchronization framework to readily use Flatland.